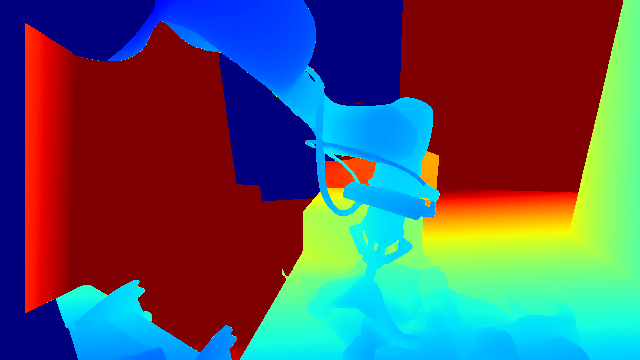
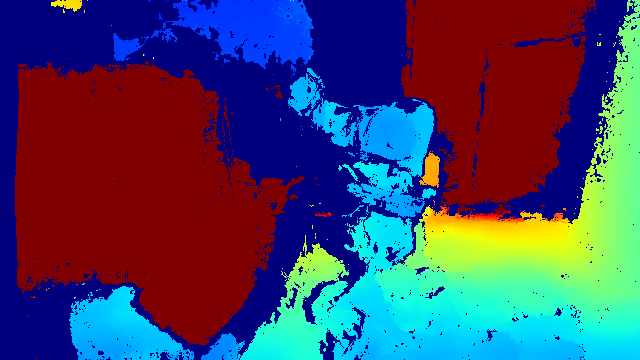
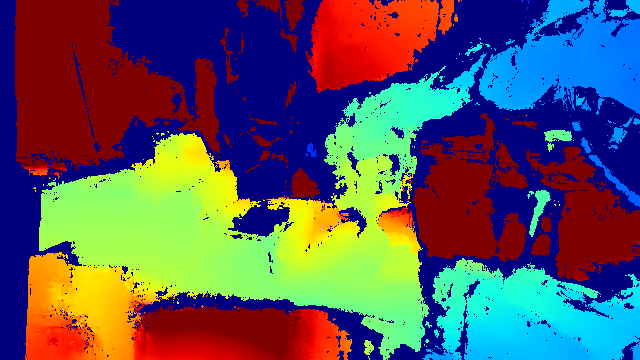
Interactive Results
Pick a scene below to view its RGB-D observations along with model predictions and corresponding ground-truth (played at 1/8× speed for clarity). All samples are unseen during training.
- Single Checkpoint: All predictions come from a single pre-trained PointWorld model.
- Inputs: Static Calibrated RGB-D Captures (t=0), Robot Point Flow (t=0...T).
- Outputs: Full-Scene 3D Point Flow (t=0...T) over the 1 m × 1 m × 1 m workspace in front of the robot.
DROID (real)
BEHAVIOR (simulated)
NOTE: The model operates on voxel-downsampled (1.5 cm) point clouds. For visual clarity, we upsample the predictions and and the ground truth by applying the same displacement to all points within each voxel. The green color in ground truth visualization indicate the points that are inaccurate due to occlusion (from 2D trackers used to provide annotations). Note that these points are not used to supervise the model, hence it's often observed that the model predicts better than the ground truth for occluded point flows after training.
Static Calibrated RGB-D Captures (Input)

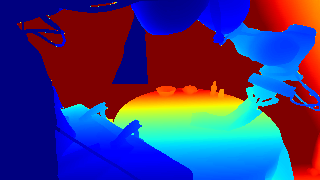


Static Calibrated RGB-D Captures (Input)